Caffe is a framework for Developing deep neural networks based applications .
The framework can be used for training a network or using the trained network for predicting or recognizing data .developed and maintained by Berkley AI Research (BAIR)
Note : Caffe is open source and documentation is less compared to other frameworks like tensor flow.
sudo apt install nvidia-cuda-toolkit
Install Caffe
sudo apt install caffe-cuda
Caffe model Zoo .
Caffe model Zoo is a repository which has thousands of pretrained models .
This repository contained pretrained models from face recognition to object recognition .
License of the models are also mentioned in the repository .
These models can be used by WIP or trained even further .
Computer Vision and Caffe .
As Deep neural networks is a vast topic which includes Machine Learning ,Computer Vision etc , we will specifically focus on Computer vision and Convolution Neural Networks (CNN) .
Convolution Neural Network .
Below is a basic diagram of a CNN network .(Most caffe model designed for Computer Vision will follow more or less the same architecture)
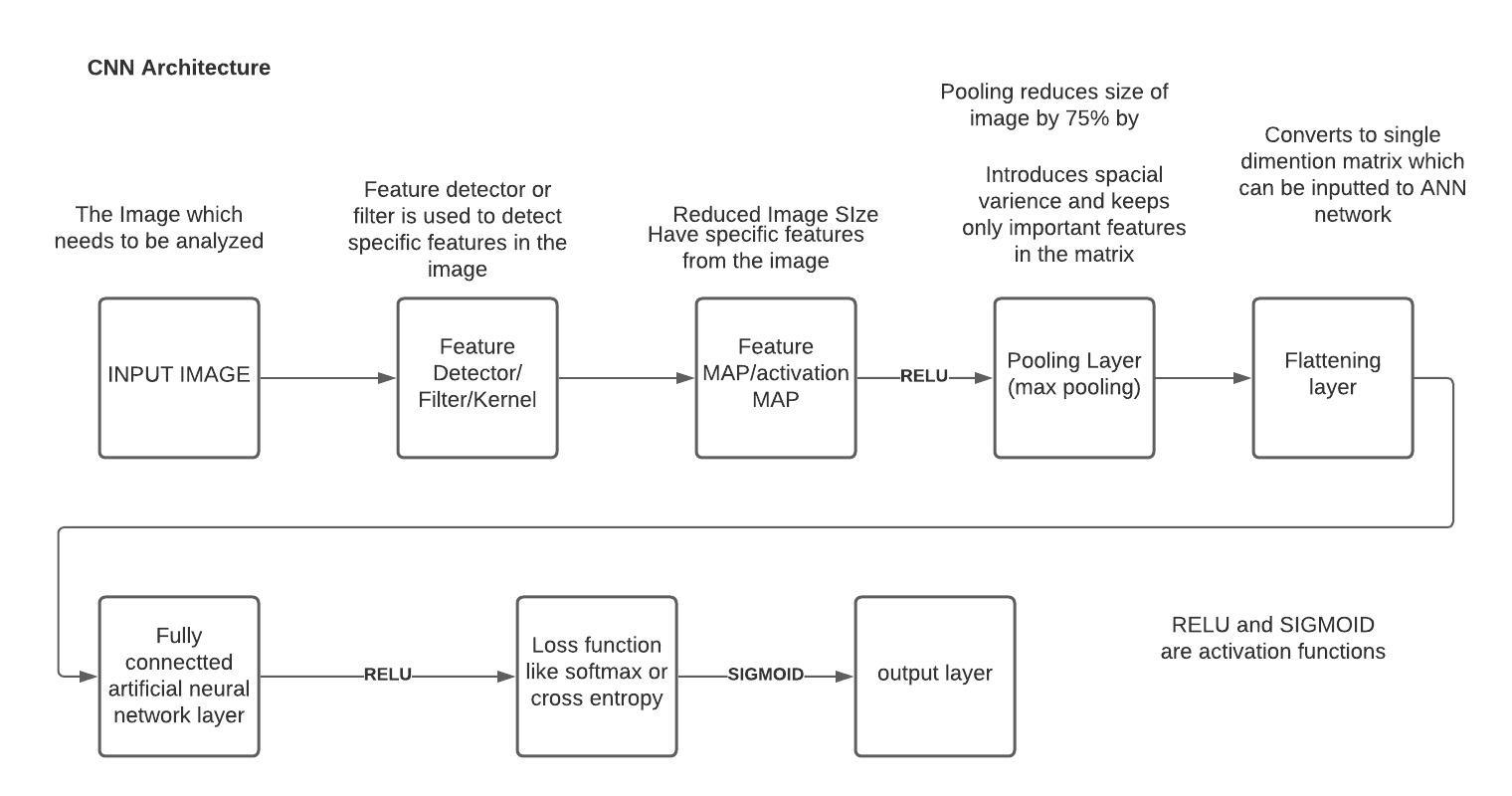
Figure 1
Caffe prototxt files
The layers which are in diagram(Figure 1) have to be defined in a prototxt file which is in protobuf format (https://developers.google.com/protocol-buffers)and is human readable .
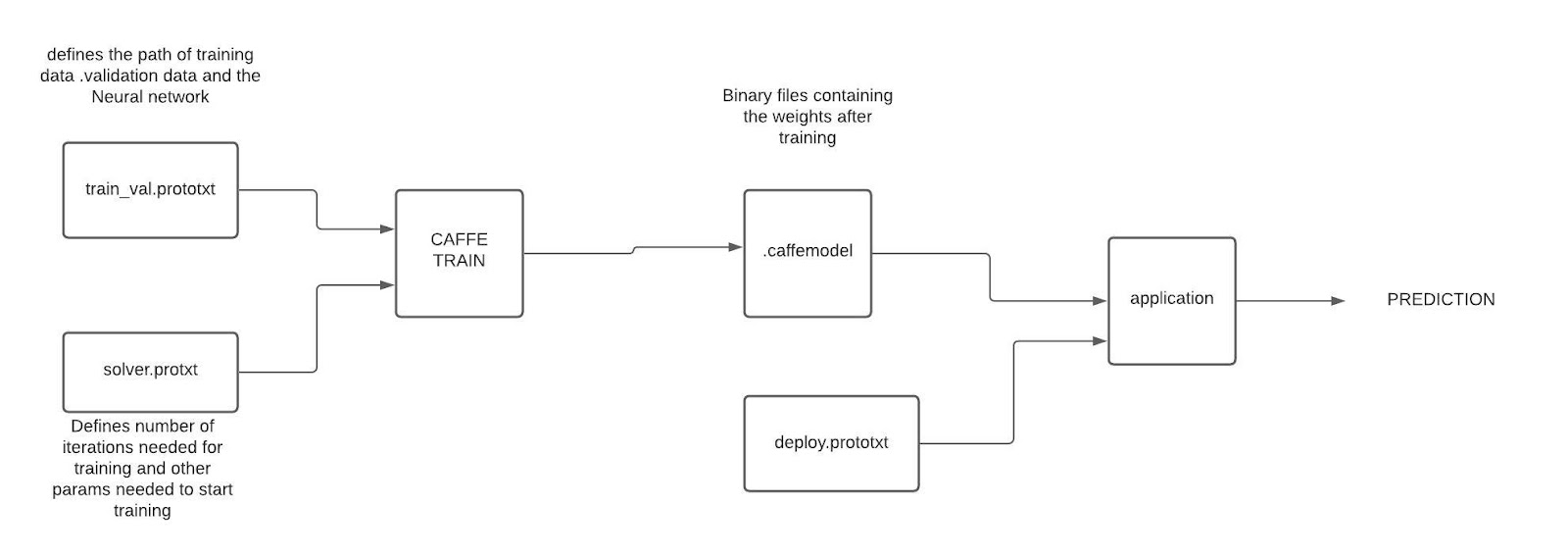
- To train a model on a new data set using caffe ,A prototxt file with the definition of the Convolution network has to be defined along with a solver.prototxt .
- Caffe train command is used along with these 2 files and a dataset of images a binary file .caffemodel is generated .
- Once the model is generated , it can be used for inference of any new images .
Below diagram shows the process
Below diagram shows the whole process
For example lets see a pretrained model from caffe Model Zoo which is used in caffe_example.tar.gz
The models definitions can be found at
https://github.com/BVLC/caffe/tree/master/models/bvlc_reference_caffenet
It has following files
- train_val.prototxt:A prototxt file used while training
- Solver.protxt :used for training the the model
- Bvlc_reference_caffenet.caffemodel : .caffemodel is the the file generated after training is complete with optimized weight values.
- Deploy.prototxt : used to predict a new picture with a already trained model which is also known as inference .
Deep learning inference is the process of using a trained DNN model to make predictions against previously unseen data.
The basic structure of the prototxt file relates to Figure 1 and is shown as below in graphical format
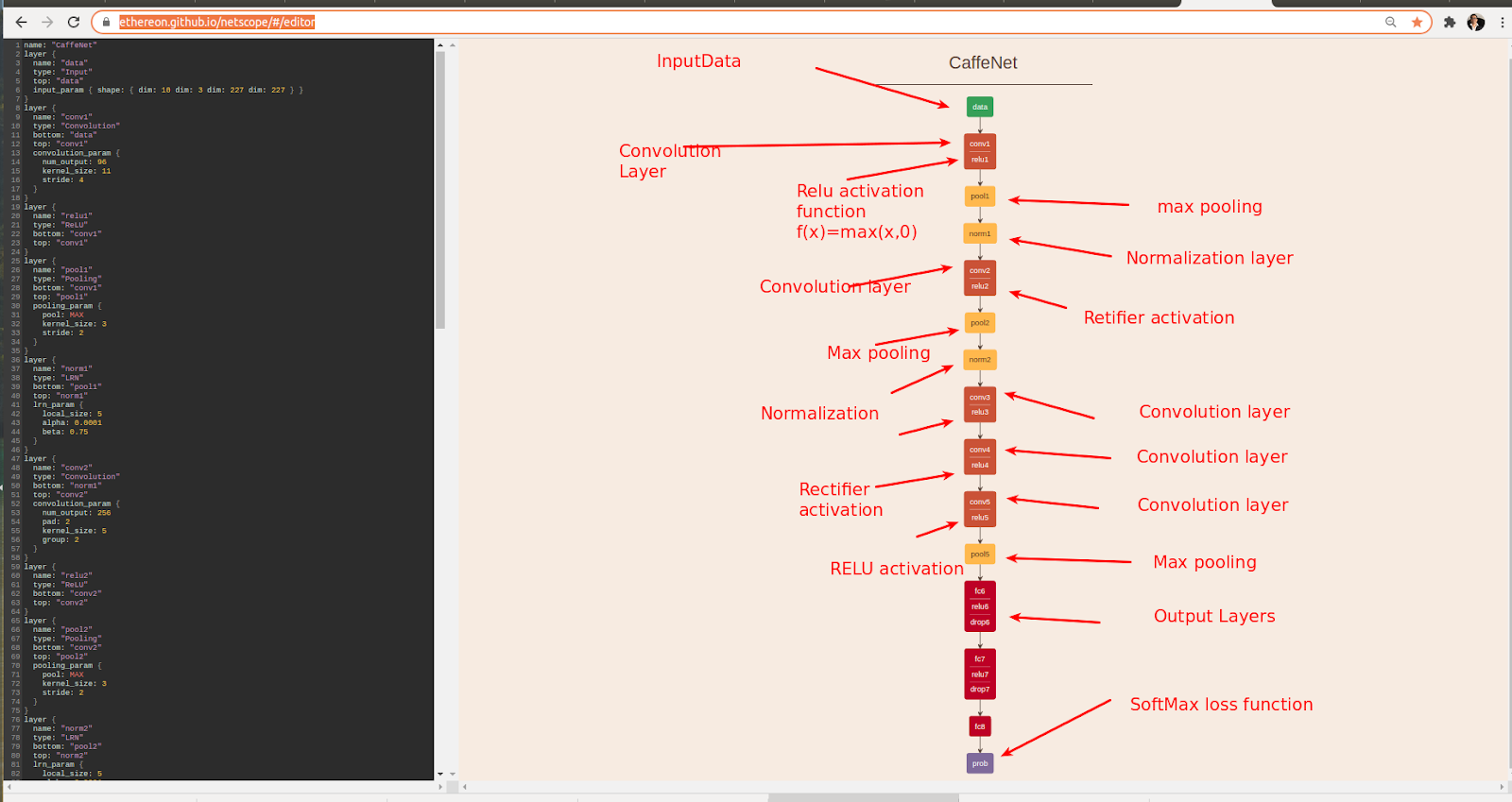
Notes:
- The online tool at https://ethereon.github.io/netscope/#/editor can be used to view a prototxt file in graphical form .
- Any new prototxt file or layers can be built using the same understanding of the layers .
- Neurosense nnaTransfer.py uses the trained model (.caffemodel and deploy.prototxt)